


AI in Market Research: the Future is… Synthetic?
The market research industry is aflutter with discussion of syntheticdata – is it the future, is it going to make traditional research redundant and what actually *is* it? As with many things featuring AI, there’s a lot of hype and confusion about what Synthetic Data is and what it can do, so here’s a primer on what it is, whether it matters, and whether it perhaps needs a rebrand. This post first appeared on LinkedIn.
As in many industries, there’s excitement about how AI might shake up research, with Mark Ritson and numerous others talking up ‘Synthetic Data’ as potentially the most transformational development. The idea is to use AI to create data and insights without needing to ask real people for their opinions, bypassing concerns about respondent and response quality, avoiding data privacy issues, and addressing the challenges of hard-to-read audiences. In short, the promise is of producing better insights faster with entirely artificial, person-free data.
With those lofty ambitions, it’s worth asking broadly, what is Synthetic Data, how does it work, and how much attention should researchers pay to it?
As it’s built on generative AI, it’s worth recapping how genAI more broadly works. Very simplistically, generative AI ingests data including facts (news, history, physics, etc), text and labelled images, then remixes and regurgitates them. So it rewrites text, cites facts and constructs images of particular visual elements, producing content that appears new and – in theory – looks like a person created it. It’s not perfect: ‘hallucinations’, made up facts and surreal images are the most obvious examples of errors; and generative AI also tends to produce content that’s identifiably AI-generated. But its efficiency and ability to parse unimaginable volumes of data make generative AI an excellent shortcut in many situations.

AI-generated content isn’t always right…
Synthetic Data works similarly: a generative AI tool ingests data, then combines and remixes it into ‘new’ content that looks like it came from a person. The input data varies, but broadly includes facts (about products, brands, purchase data etc), attitudes and consumer behaviours. These are gathered and scraped from sources including social media platforms, news articles, relevant industry research reports, reviews from Trustpilot and so on; proprietary data such as clients’ customer satisfaction results, support tickets, SKU information and the like are also included.
After processing this data, the AI tool creates ‘virtual respondents’ and their virtual attitudes and virtual survey responses.
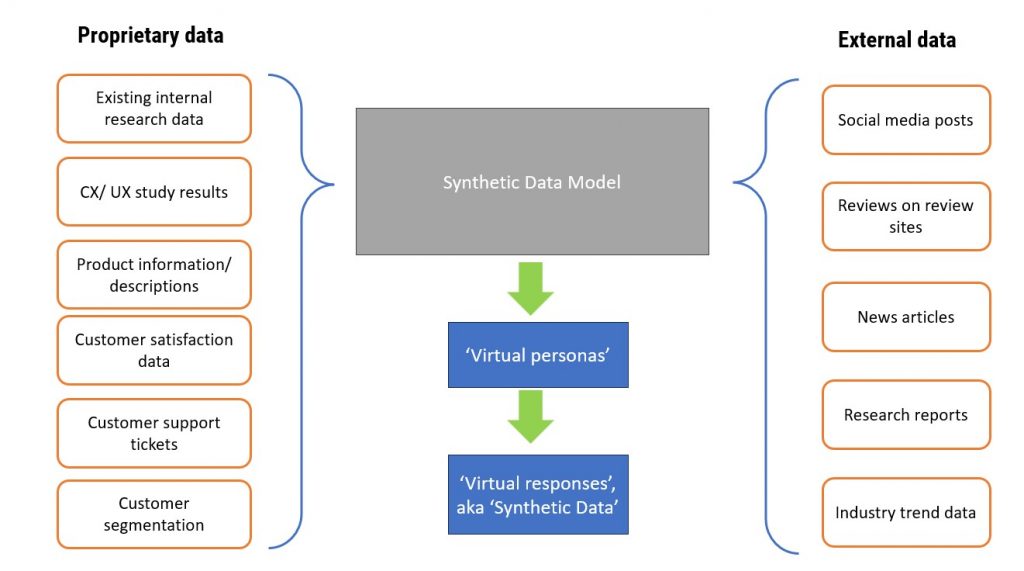
The genAI model ingests external and proprietary data, then remixes it into ‘virtual responses’ (ie Synthetic Data)
As with genAI more broadly, it’s not creating new data; rather it’s remixing existing data into new combinations that look like new data – and that distinction is important.
As an approach it’s not without challenges, with data quality the most obvious. In order to produce useable outputs, the ingested data must be timely – public opinions of Boeing, for example, have shifted wildly in the last three months. And it has to be an accurate representation: online reviews tend to be written by people with something to say, so may not be the best source for modelling customer opinions across a whole market.
The bigger problems lie in what Synthetic Data apparently solves.
First, it purports to create lifelike answers to research questions without actually needing to find and survey real people. It sounds good, but as noted above, one of the data types that’s used in Synthetic Data is custom research – i.e. actual answers from actual people. It boils down to this idea of remixing: genAI is very good at outputting something that looks like data it has ingested (e.g. people’s answers to specific questions), but less able to extrapolate one data type from another data type. So for Synthetic Data to produce survey responses, you generally need to input survey data – and you’d usually want that to be as recent and as robust as possible. Which seems… less useful.
Another lauded benefit of Synthetic Data is that it addresses the difficulties of understanding hard-to-reach populations and minority groups; the idea being that even if we can only solicit opinions from 10 people of a particular audience, we can increase that sample size – and the robustness of our data – by ‘creating’ relevant respondents and their responses.
It’s a beguiling proposition: at a stroke we can ensure that research properly represents the views of traditionally under-represented and overlooked groups.
But it too ignores the nature of remixing rather than creating data: if our new ‘virtual respondents’ are based on the opinions, attitudes and behaviours of only 10 actual people known to be in our target audience, then regardless of how much data we ‘create’, its core is still a sample size of 10, with all the data quality and skew issues that entails.
Probably the biggest challenge facing Synthetic Data is that none of this is really anything new. A good research team working on any research project will already start with robust desk research, bringing together industry context, proprietary research, customer data and sometimes social media highlights in order to understand what makes audiences tick – just like Synthetic Data platforms promise to do.
So, if we strip away the buzz and marketing bumf, where does that leave Synthetic Data?
At its core it supercharges the process of desk research and collating contextual insights, processing vastly more data, and seeing links and themes much more rapidly and efficiently than people can; so it has the potential to become an invaluable supplementary tool for researchers, like qualitative chatbots and LLM-based coding tools.
But it’s not going to change the essential shape of market research; it obviously doesn’t replace response-based research such as surveys and focus groups, and any researcher worth their salt will still need to ask real flesh and blood people for their opinions. And it probably needs a rebrand: Synthetic Data sounds amazing, but really, it’s best thought of as Enhanced Contextual Data, or something equally accurate but uninspiring.
For me, the final word on this is a quote from Sean McDonald of Rethink:
Is AI the future? AI is part of the future. But so is the next thing. And so are the three other things that are still happening from the past. I’m a little bit bored of it, to be honest. Because I think people get more excited by the shiny objects than they do about doing the hard work and just challenging themselves to be excellent with any tools that they have. And I think our industry should really double down on enabling people to do great work, leveraging whatever tools they have in place. And if AI is one of those tools, fantastic. But I think we get more excited about these tools than we do about the conditions and the people that really lead to great work. And so I lament that a little bit. I think people are always going to be the future. And I think there’s going to be a litany of tools to help them.

